一元线性回归
回归模型参数估计
最小二乘估计
最小二乘估计(Least Square Estimation ,OLE):根据观察数据,寻找参数$\beta_0$,$\beta_1$的估计值$\hat{\beta_0}$,$\hat{\beta_1}$,使观测值和回归预测值的离差(离开正确值的差)平方和达到极小。估计值$\hat{\beta_0}$,$\hat{\beta_1}$称作回归参数$\beta_0$,$\beta_1$的最小二乘估计。
列出离差平方和:
估计值满足:对$Q(\beta_0,\beta_1)$分别求$\beta_0$,$\beta_1$的偏导,并令其等于0,即求$Q(\beta_0,\beta_1)$取极小值时$\beta_0$,$\beta_1$的取值,这取值即为估计值$\hat{\beta_0},\hat{\beta_1}$的值。


最大似然估计
最大似然估计(Maximum Likelihood Estimation,MLE):利用总体的分布密度或概率分布的表达式及其样本所提供的信息求未知参数估计量的一种方法。
最大似然估计的基本思路:已知样本符合某种分布,但分布的具体参数未知,通过实验,估算分布的参数。估算的思想为:已知某组参数能使当前样本出现的概率最大,就认为该参数为最终的估计值。

回归模型的显著性检验
回归系数是否显著:t检验
因变量y与自变量x之间是否存在线性关系,即$\beta_1$是否等于0,使用t检验进行判断。
- 确定假设:我们搜集数据是为了找到不达标的而证据,即原假设$H_0: \beta_1 = 0$,备择假设$H_1: \beta_1 \ne 0$
- 确定检验水平:采取最常用的$\alpha=0.05$,或是更严格的$\alpha=0.01$
- 构造统计量:$H_0$成立时:, 构造t统计量:
- 比较p值和$\alpha$值:计算t统计量,符合自由度n-2的t分布,双尾检测,查临界值表,找到p值
- 得到结论:p值若大于$\alpha$值,不能拒绝原假设。即通过本次采样得到的样本数据,并不能证明原假设$H_0$不成立,即本次得到的回归系数$\beta_1$无显著意义,需重新建模。
回归方程是否显著:F检验
F检验是根据平方和分解式,直接从回归效果检验回归方程的显著性。由平方和分解式可得到SSR越大,回归效果越好,据此构造F统计量。

- 确定假设:我们搜集数据是为了找到不达标的而证据,即原假设$H_0: \beta_1 = 0$,备择假设$H_1: \beta_1 \ne 0$
- 确定检验水平:采取最常用的$\alpha=0.05$
- 计算统计量:计算F统计量,原假设$H_0$其服从自由度为(k-1,T-k)
- 计算p值:F=156.9,degree=(1,13),$p=1.284*10^{-8}$

- 得到结论:p<$\alpha$,拒绝原假设$H_0$,接受备择假设$H_1:\beta_1 \ne 0$
相关系数显著性检验:t检验
相关系数(Correlation Coefficient)由卡尔·皮尔逊设计的统计指标,描述了变量之间线性相关程度的量,一般用字母r表示,由多种定义方式,一般是指皮尔逊相关系数。
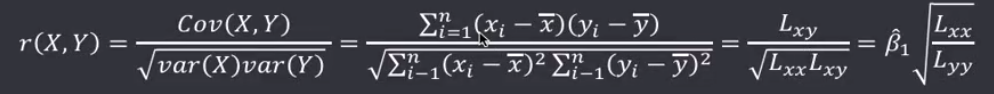
- 确定假设:我们搜集数据是为了找到不达标的而证据,即原假设$H_0: \rho = 0$,备择假设$H_1: \rho \ne 0$
- 确定检验水平:采取最常用的$\alpha=0.01$
- 计算统计量:计算t统计量,原假设$H_0$成立,$t=\frac{\sqrt{n-2r}}{1-r^2}$
- 计算p值:n=15,r=0.9610,t=13.07,计算得到$p=7.432\times 10^{-9}$(也可以查相关临界值表,查到$\alpha=0.01$,degree=13对应的值为10.641,小于计算得到的t值)
- 得到结论:p<$\alpha$,拒绝原假设$H_0$,接受备择假设$H_1:\rho \ne 0$
决定系数
通过平方和分解式SST=SSR+SSE,SSR占的比重越大,线性回归效果越好,即回归直线与样本观测值的拟合优度越好。定义回归平方和占总离差平方和的比例为决定系数(Coefficient of Determination),也称确定系数,记作$r^2$:
决定系数是一个相对指标,取值在0~1之间,接近1表明回归方程拟合效果较好。但是需要注意几点:
- 样本量较小时,决定系数并不能真正反应实际情况,需要调整决定系数
- 决定系数较大,同样也不能肯定自变量与因变量之间关系就是线性的,可能曲线拟合更好,特别当自变量取值范围较小时,决定系数通常较大,可以做模型失拟检验(Lack of Fit Test)
- 决定系数较小,如果样本量较小,则得到线性回归不显著的结果,如果样本量较大,则会得到线性回归显著;最后改进回归,如增加自变量、尝试曲线回归拟合等
残差
残差的基本概念
以一元回归为例,真实值与回归拟合值(模型输出)的差,称作残差(Residual)。
残差:$e_i=y_i-\hat{y_i}$
残差平方和:$\sum_{i=1}^n e_i^2 =\sum_{i=1}^n (y_i-\hat{\beta_0}-\hat{\beta_1}x_i)^2$
几个常见“差”的概念:
- 误差:真实值与模型输出值的差$\varepsilon_i=y_i-\beta_0-\beta_1x_i$
- 残差:真实值与模型拟合值(估计值)的差,即为误差的估计值:$e_i=y_i-\hat{y_i}=y_i-\hat{\beta_0}-\hat{\beta_1}x_i$
- 离差:真实值与模拟拟合值的期望(平均值)的差,离差平方和为:$SST=(y_i-\bar{y})^2$
- 偏差:事实上的真实值(不可知)与估计值的差:$bias=y_T-\hat{y_i}$
- 方差:模型估计值与模型估计值的期望(平均值)的方差:$var=\sum_{i=1}^n(\hat{y_i}-\bar{y})^2$
残差的性质
残差的期望
残差的约束条件
残差的方差
其中$h_ii$称为杠杆值,取值为(0,1)
残差改进方法
标准化残差 $ZRE_i=\frac{e_i}{\hat{\sigma}}$
- 标准化使残差可比
- 可用其判断异常值,$|ZRE_i|>3$
- 无法处理方差不等的问题
学生化残差 $SRE_i=\frac{e_i}{\sigma \sqrt{1-h_{ii}}}$
- 解决了方差不等的问题
- 可根据$|SRE_i|>3$判断异常值
模型应用
预测
- 单值预测:根据自变量和回归方程预测因变量的单个值:$\hat{y_0}=\hat{\beta_0}+\hat{\beta_1}x_0$
区间预测:
- 思路:显著水平$\alpha$,找到区间$(T_1,T_2)$,使得某特定$x_0$的实际值$y_0$以$1-\alpha$的概率在该区间内,即:$P(T_1 < y_0 < T_2)=1-\alpha$
因变量新值的区间预测
预测因变量在某个置信度的取值区间
因变量新值的均值区间预测
预测因变量的均值在某个置信度的取值区间
控制
控制时预测的反问题。
要把因变量y控制在一定范围内取值$T_1 < y < T_2$,需要控制x的值才能以$1-\alpha$的概率把目标值y控制在$(T_1,T_2)$中,即:$P(T_1 < y_0 < T_2)=1-\alpha$,其中$\alpha$时实现给定的(0,1)之间的小数,用来确定置信度。




