机器学习的基本概念
输入空间
输入‘X’可能取值的集合就是输入空间(input space)。输入空间可以是有限集合空间,也可以是整个欧式空间。
输出空间
输出‘Y’可能取值的集合就是输出空间(output space)。输出空间可以是有限集合空间,也可以是整个欧式空间。
假设空间
假设空间一般是对于学习到的模型而言的。模型表达了输入到输出的一种映射集合,这个集合就是假设空间,假设空间表明着模型学习的范围。
特征空间
每一条样本被称作是一个实例,通常由特征向量表示,所有特征向量存在的空间称为特征空间。特征空间有时候与输入空间相同,有时候不同(例如word embbeding),不同的情况是输入空间通过某种映射生成了特征空间。
机器学习的实质
在输入空间到输出空间中的各种假设形成的假设空间中去搜索一个假设,这个假设对当前的数据拟合情况最好。
机器学习的三要素
- 模型
- 策略
- 算法
损失函数
针对单个具体样本,表示模型预测值与真实样本值之间的差距。损失函数越小,说明模型对于该样本预测越准确。常见损失函数有0-1损失函数、平方损失函数、绝对损失函数、对数损失函数(对数似然损失函数)。
常见的损失函数

经验风险和结构风险
确定了损失函数后,那么自然地损失函数越小越好,由于模型的输入X,输出Y 是随机变量,遵循联合分布P(X, Y),所以损失函数的期望为:
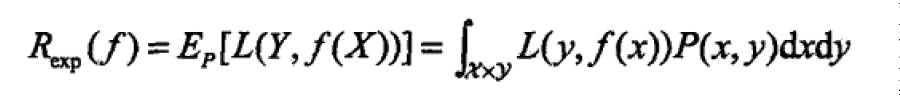
我们将上面提到的训练集的总损失定义为经验风险,如下所示:
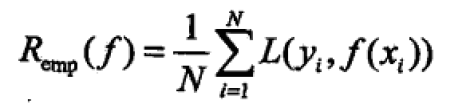
将损失的期望称为期望风险,如下所示:
怎样求风险?
机器学习问题求的是条件概率,那么有人就说了,既然上面提到了两随机变量的联合分布,那么我们根据条件概率-联合概率-边缘概率的关系岂不是可以直接求解?
其实,我们手头无法得到全体样本,因此,联合概率 P(X, Y) 是无法得到的,但是根据弱大数定律,当样本N无限大时,可用经验风险作为期望风险的估计,也就是局部估计整体。
那么我们常说的风险最小化其实就指的是经验风险最小化!
为何引入结构化风险?
虽然可以使用经验损失近似估计期望风险,但是大数定理的前提是N无穷大,实际上,我们的训练集一般不会特别大,此时就需要对经验风险做出适当调整才能近似估计。因此引入结构风险。
结构化风险是为了缓解数据集过小而导致的过拟合现象,其等价于正则化,本质上反应的是模型的复杂度。认为经验风险越小,参数越多,模型越复杂,因此引入对模型复杂度的惩罚机制。定义如下:
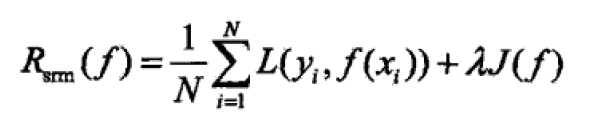
正则化被定义为模型复杂度的单调函数,λ用于权衡经验风险与模型复杂度。
至此,我们认为结构风险最小化的模型是最优模型,因此,我们的优化问题变为:
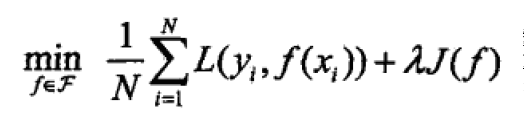
结构化风险本质
结构化风险(正则项)其实是加入了模型参数分布的先验知识,也就是贝叶斯学派为了将模型往人们期望的地方去发展,继而加入了先验分布,由于是人为的先验,因此也就是一个规则项(这也就是正则项名称的由来)。这样一来,风险函数将进一步考虑了被估计量的先验概率分布。
参考资料和相关网址
经验风险、期望风险、结构风险:
https://www.jianshu.com/p/903e35e1c95a



