模型评估与选择
模型选择
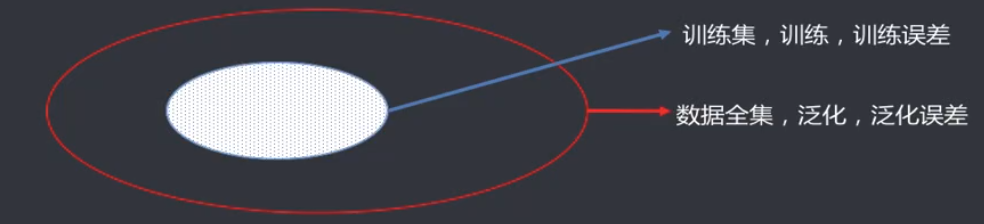
误差
误差
误差(Error):是模型的预测输出值与其真实值之间的差异。
训练
训练(Training):通过已知的样本数据进行学习,从而得到模型的过程。
训练误差
训练误差(Training Error):模型作用于训练集时的误差。
泛化
泛化(Generalize):由具体的、个别的扩大为一般的,即从特殊到一般,称为泛化。对机器学习的模型来讲,泛化是指模型作用于新的样本数据(非训练集)。
泛化误差
泛化误差(Generalize Error):模型作用于新的样本数据时的误差。
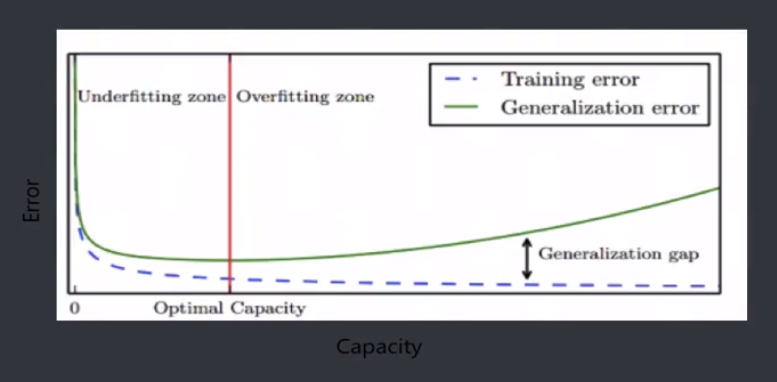
欠拟合和过拟合
模型容量
模型容量(Model Capacity):是指其你和各种模型的能力。
过拟合
过拟合(Overfitting):是某个模型在训练集上表现得很好,但是在新样本上表现差。模型将训练集的特征学习得太好,导致一些非普遍规律被模型接纳和体现,从而在训练集上表现好,但是对于新样本表现差,反之则称为欠拟合(Underfitting),即模型对训练集的一半性质学习较差,模型作用于训练集时表现不好。
模型选择
模型选择(Model Selection):针对某个具体的任务,通常会有多种模型可供选择,对同一个模型也会有多组参数,可以通过分析、评估模型的泛化误差,选择泛化误差最小的模型。
选择图中红线位置的模型:
模型评估
评估思路
通过实验测试,对模型的泛化误差进行评估,选出泛化误差最小的耳模型。待测数据集全集未知,使用测试集进行泛化测试,测试误差(Testing Error)即为泛化误差近似。

评估方法
1. 留出法
留出法(Hold-out):将已知数据集分成两个互斥的部分,其中一部分用来训练模型,另一部分用来测试模型,评估其误差,作为泛化误差的估计。
两个数据集的划分要尽可能保持数据分布一致性,避免因数据划分过程引入为的偏差。
数据分割存在多种形式会导致不同的训练集、测试集划分,单次留出法结果往往存在偶然性,其稳定性较差,通常会进行若干次随机划分、重复实验评估取平均值作为评估结果。
数据集拆分成两部分,每部分的规模设置回影响评估结果,测试、训练的比例通常为7:3、8:2等
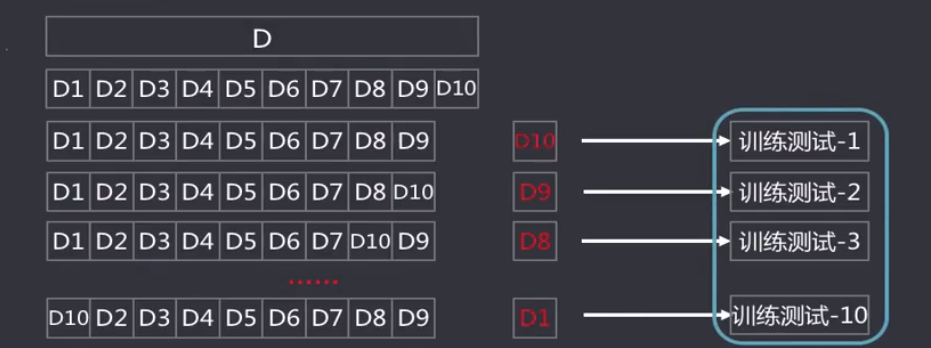
2. 交叉验证法
交叉验证法(Cross Validation):将数据集划分k个大小相似的互斥的数据子集,子集数据尽可能保证数据分布的一致性(分层采样),每次从中选取一个数据集作为测试集,其余用作训练集,可以进行k次训练和测试,得到评估均值。该验证方法也称作k折交叉验证(k-fold Cross Validation)。使用不同划分,重复p次,称为p次k折交叉验证。
3. 留一法
留一法(Leave-One-Out,简称LOO)。是k折交叉验证的特殊形式,将数据集分为两个,其中一个数据集记录条数为一,作为测试集使用,其余记录作为训练集训练模型。因此,留一法的评估结果往往被认为比较准确。然而,在数据集比较大时,训练次数和计算规模较大。另外,留一法的估计结果也未必永远比其他评估方法准确。
4. 自助法
自助法(Bootstrapping):是一种产生样本的抽样方法,其实质是有放回的随机抽样。即从已知数据集中随机抽取一条记录,然后将该记录放入测试集同时放回原数据集,继续下一次抽样,直到测试集中的数据条数满足要求。




